任何有兴趣了解有关构建 AI 聊天应用程序的更多信息的人。有兴趣知道IBM已经创建了一个非常快速和中肯的介绍,以使用检索增强生成(RAG)和大型语言模型。通过构建自己的聊天应用程序并使用您自己的个人数据对其进行自定义,使它们更有价值。无论您是希望保留第三方服务器的文档还是具有敏感数据的企业的个人。根据特定信息和知识训练您自己的 AI 模型是将 AI 集成到工作流程中的好方法。
重点介绍 RAG、LangChain 框架和 Streamlit 组件的使用。它还将就使用LangChain的接口作为凭证字典和IBM Cloud的API以及使用大型语言模型“Llama 2 70b聊天”进行项目的一些见解。
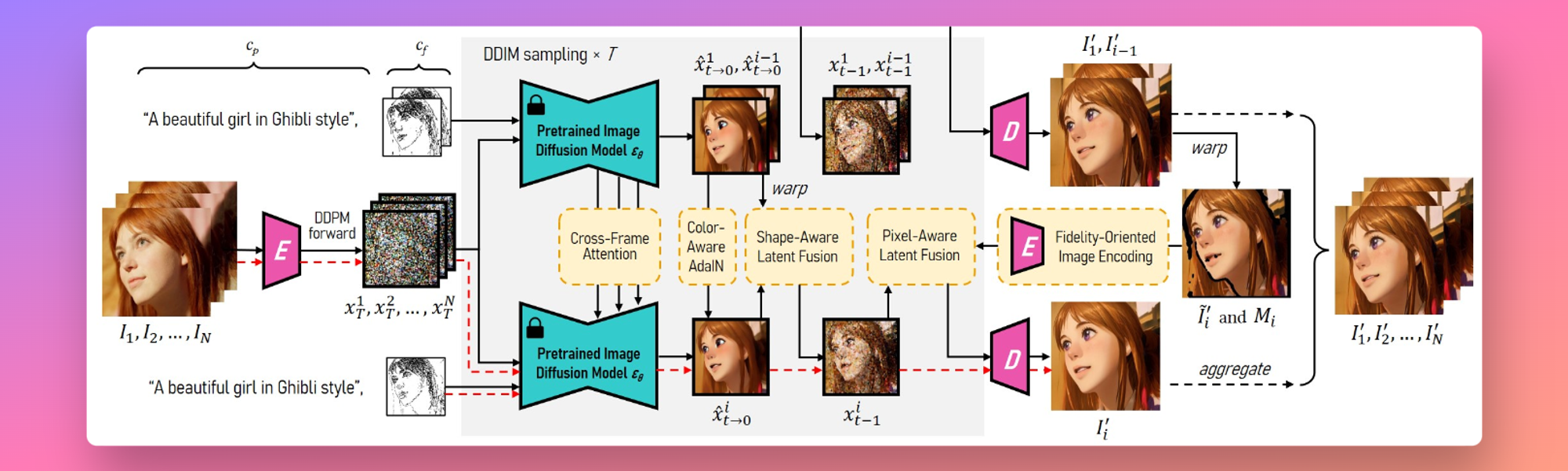
检索增强生成 (RAG) 技术是一种强大的工具,它结合了基于检索和生成模型的优势,用于自然语言理解和生成任务。在这种方法中,初始查询或上下文用于使用检索器从大型数据库或语料库获取相关信息。然后将检索到的信息提供给生成器模型,通常是像变压器这样的序列到序列模型,以产生更明智且上下文相关的输出。在使用大型语言模型和个人数据构建聊天应用的上下文中,此技术可能非常有益。它允许应用程序提供不仅连贯且适合上下文的响应,而且还根据用户的数据提供高度个性化的响应。
使用 LLM 构建 AI 聊天应用程序
LangChain是一个专为开发由语言模型驱动的应用程序而设计的框架。它为使用语言模型所需的组件提供了模块化抽象,并具有这些抽象的实现集合。这些组件被设计为易于使用,无论您是否使用LangChain框架的其余部分。 Nicholas Renotte将带您完成使用LangChain和Streamlit构建聊天应用程序的过程,在短短三分钟内涵盖您需要了解的所有内容。
LangChain 还提供了特定于用例的链,可以将其视为以特定方式组装这些组件以最好地完成特定用例。这些链被设计为可定制的,并提供更高级别的界面,人们可以通过该界面轻松开始使用特定用例。
使用流光轻松进行 GUI 设计
使用 LangChain 和 Streamlit 构建聊天应用程序可以提供无缝且高效的开发体验。流光组件可用于聊天输入和消息显示,从而创建用户友好的界面。可以创建一个状态变量来存储用户提示,从而简化跟踪和响应用户交互的过程。LangChain与WhatOnNext的界面可用于指导聊天应用程序的响应,使其更具活力和吸引力。
llama 2
对于该项目,可以使用大型语言模型“llama 2 70b chat”。该模型可以生成连贯且上下文适当的响应,从而增强用户体验。语言模型生成的响应可以使用 Streamlit 聊天消息组件显示,从而为用户创建流畅的交互式界面。
“Llama 2 是预训练和微调的生成文本模型的集合,规模从 7 亿到 70 亿个参数不等。这是 70B 微调模型的存储库,针对对话用例进行了优化,并针对拥抱面变压器格式进行了转换。其他模型的链接可以在底部的索引中找到。
添加个人数据
将个人数据合并到聊天应用程序中可以通过多种不同的方式完成。例如,将PDF数据加载到LangChain Vector存储索引中。这允许应用程序从PDF文件中检索和利用个人数据,为聊天交互添加个性化层。LangChain 检索器 QA 链可用于与 PDF 数据的聊天交互,使应用程序能够根据用户的个人数据提供响应。
为了便于连接到外部数据源和服务,凭证字典可以与 IBM Cloud 的 API 一起使用。这允许聊天应用访问和利用基于云的资源,从而增强其功能和性能。
使用大型语言模型和个人数据构建聊天应用涉及先进技术和工具的组合。使用检索增强生成技术、LangChain 框架和 Streamlit 组件,以及个人数据的集成,可以产生动态、交互式和个性化的聊天应用程序。这个过程虽然复杂,但可以提供有益的结果:聊天应用程序不仅可以理解和响应用户提示,还可以提供个性化和引人入胜的用户体验。
未经允许不得转载:表盘吧 » 使用大型语言模型和个人数据构建 AI 聊天应用