所有文章第345页
既然是数学模型,那应该如何计算呢? 最简单的方法,当然就是用统计学的方法去计算了,简单说来,就是靠输入的上下文进行统计,计算出后续词语的概率,比如「你吃了晚饭了吗」,「你吃了」后面按照概率,名词如「饭」或「晚饭」等概率更高,而不太可能是动词,如「睡」「睡觉」。 这是语言模型的第一阶段,模型也被称为是统计语言模型(Statistical Language Mo...
LLMs 全称是 Large Language Models,中文是大语言模型。 那么什么是语言模型? 语言模型简单说来,就是对人类的语言建立数学模型,注意,这里的关键是数学模型,语言模型是一个由数学公式构建的模型,并不是什么逻辑框架。这个认知非常重要。 最早提出语言模型的概念的是贾里尼克博士。 他是世界著名的语音识别和自然语言处理的专家,他在 IBM 实验...
在示例里加入特定符号,让模型知道如何处理特殊情况 这个解释起来有点复杂,以下是 OpenAI 的官方 prompt,在一些奇怪的问题上比如 What is Devz9 的回答,你可以用 ? 代替答案,让模型知道当遇到超出回答范围时,需要如何处理(注意:此方法在 playground 上有效,但在 ChatGPT 上无效)。 Q: Who is Batman...
![]() 2
2基于上述的第三点缺点,研究人员就找到了一个叫 Chain of Thought 的技巧。 这个技巧使用起来非常简单,只需要在问题的结尾里放一句 Let‘s think step by step (让我们一步步地思考),模型输出的答案会更加准确。 这个技巧来自于 Kojima 等人 2022 年的论文 Large Language Models are Zer...
假设你想让 AI 总结一篇非常非常长的文章,并且按照特定格式给你总结,那你可以在文章前面明确输出的格式(为了不占用太多显示空间,我省略了正文内容,你可以在 OpenAI 的 Playground 看到完整案例)。它的意思其实是让 ChatGPT 按 Topic 总结,每个 Topic 里按照无序列表(就是里面那个 -)将每个 Topic 的主要观点罗列出来。...
可以用“”“将指令和文本分开。根据我的测试,如果你的文本有多段,增加”“”会提升 AI 反馈的准确性(这个技巧来自于 OpenAI 的 API 最佳实践文档) 信息 感谢 CraneHuang6 的提醒,这里还能用 ### 符号区隔,不过我一般会用“”“ ,因为我有的时候会用 # 作为格式示例,太多 # 的话 prompt 会看起来比较晕 😂 像我们之前写的...
比如还是上面那个 rewrite 的例子,我在例子前加入这样的一段话,我让 AI 假设自己是一个小学老师,并且很擅长将复杂的内容转变成 7、8岁小朋友也能听懂的话,然后再改写这段话: You are a primary school teacher who can explain complex content to a level that a 7 or ...
在代码生成场景里,有一个小技巧,上面提到的案例,其 prompt 还可以继续优化,在 prompt 最后,增加一个代码的引导,告知 AI 我已经将条件描述完了,你可以写代码了。 Better: Create a MySQL query for all students in the Computer Science Department: Table dep...
![]() 1
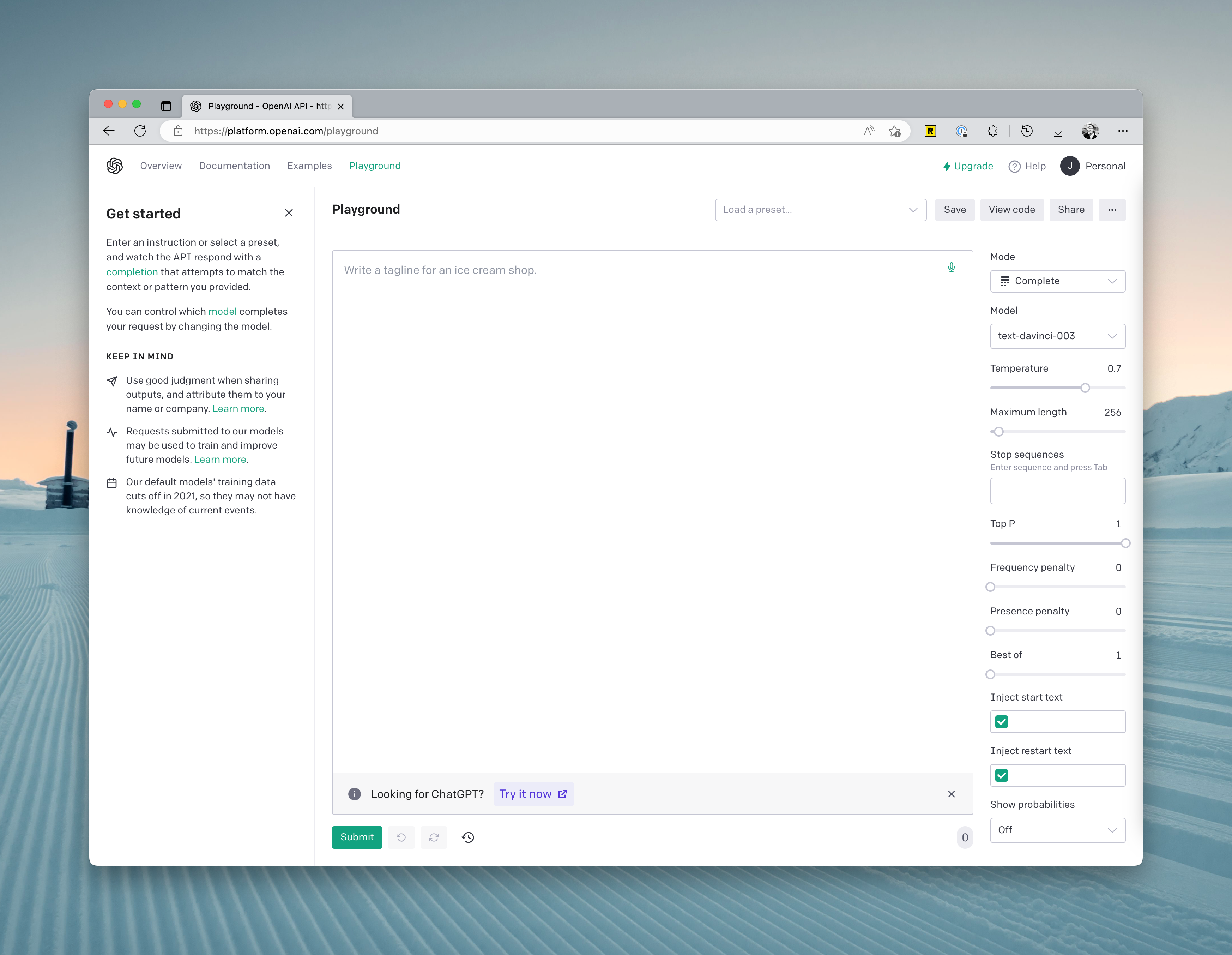
1如果你想要更好地了解 OpenAI 的 API,并且你常常会遇到 ChatGPT 不可用的情况。那我建议你使用 OpenAI 的 Playground。它会比较稳定。 但需要注意,这个 Playground 会消耗你的免费 Credit。 你会在界面的右侧看到以下几个参数: Mode: 最近更新了第四种 Chat 模式,一般使用 Complete 就好,当然...
在问答场景里,为了让 AI 回答更加准确,一般会在问题里加条件。比如让 AI 推荐一部电影给你 Recommend a movie to me 。但这个 prompt 太空泛了,AI 无法直接回答,接着它会问你想要什么类型的电影,但这样你就需要跟 AI 聊很多轮,效率比较低。 所以,为了提高效率,一般会在 prompt 里看到类似这样的话(意思是不要询问我对...
 如何在 Windows 11 上选择默认扬声器阅读(3425)
如何在 Windows 11 上选择默认扬声器阅读(3425)